I tuoi amici nerd ti bullizzano perché usi ancora software proprietario come Telegram e non sei migrato a Matrix? Rilancia hostando con Prosody il tuo server XMPP personale! (Sì, il vecchio caro Jabber di fine anni ’90…)
Consumando solo una 40ina di MB di RAM e pochi MB di disco può girare su piccoli server virtuali, sistemi embedded, hardware di recupero… Grazie alle librerie di gateway Slidge puoi creare dei bridge verso altri network come WhatsApp o Telegram proprio come fa Matrix.
Per rendere il server XMPP ancora più sicuro e far rosicare i tuoi amici consiglio di non renderlo disponibile in chiaro su Internet, ma tramite reti anonime come TOR, Yggdrasil o I2P.
Basterà installare il pacchetto “prosody” sulla vostra distro preferita e configurarlo come segue:
Se vogliamo lasciare che i nuovi utenti possano creare un account basterà scrivere nel file di configurazione /etc/prosody/prosody.cfg.lua
allow_registration = true
Altrimenti (scelta consigliata se vogliamo gestire una piattaforma per pochi intimi) possiamo creare manualmente gli utenti col comando
prosodyctl adduser
A seguire un esempio di file prosody.cfg.lua È stata permessa la creazione di utenti e oltre al server principale su Yggdrasil ci sono due virtualhost su TOR e I2P. Non ho abilitato tls perché non mi serve dato che lo uso su reti già cifrate, mentre il modulo “muc” serve per la creazione di stanze
L’ostacolo principale per l’affermazione di una nuova tecnologia non è la sua complessità, ma l’esistenza di una tecnologia precedente che riesca, sebbene in maniera parziale, a svolgerne funzioni simili.
Questo è il motivo per il quale, nonostante l’IPv6 e le connessioni Internet a banda larga esistano da oltre 20 anni, l’utente medio impreca ancora col NAT e non può godersi un IP statico.
La rete Yggdrasil, che non ha niente a che fare con la storica distribuzione Linux Plug&Play dei primi anni ’90, vi permetterà di sperimentare l’ebrezza di avere un IPv6 statico bypassando l’inerzia dei vostri provider! Si tratta infatti di una rete mesh VPN IPv6 con cifratura end-to-end, praticamente una rete privata dove ogni partecipante è sia host che client, che si auto-organizza senza autorità centrale e che cifra tutte le connessioni.
Funzionalità
Mesh Networking: protocollo di routing distribuito basato su una Distributed Hash Table (DHT), simile a Kademlia. Ogni nodo si connette ad altri nodi formando una rete, a differenza di quanto accada con le normali reti geografiche.
Cifratura end-to-end: tutto il traffico è cifrato in maniera simile ad una VPN, ma integrato. Più o meno come era stata pensata la cifratura nativa di IPv6 con IPsec.
IPv6 nativo: Assegna indirizzi IPv6 univoci e permanenti, basati sull’hash di una chiave pubblica che genera al primo avvio
In pratica
1) Si installa il software Yggdrasil sul dispositivo 2) Ci si connette ad almeno un altro nodo Yggdrasil (un amico, un server pubblico) impostandolo su /etc/yggdrasil.conf 3) Il programma scopre automaticamente altri nodi e crea i percorsi ottimali 4) Viene creata una nuova interfaccia di rete tun0 alla quale è attribuito un indirizzo IPv6 univoco (es.: 200:x:x:x::/64) 5) Adesso si è pronti per comunicare con qualsiasi altro dispositivo presente sulla rete Yggdrasil
Casi d’uso principali
Alternativa (a prova di utonto) ai tradizionali software VPN come Wireguard o OpenVPN
Alternativa a VPN commerciali
Comunicazioni sicure senza dipendere dalla cifratura del protocollo di comunicazione (http, ftp, telnet, imap…)
Reti comunitarie in aree con internet limitato (es. università, laboratori, uffici…)
Creazione di servizi decentralizzati (chat, file sharing, hosting)
Avevo bisogno di un serverino domestico per alcuni esperimenti e per taccagneria passione per il trashware ho deciso di recuperare il mio “vecchio” (2007) EeePC 701 (Celeron M 900MHz, 2GB RAM, 4GB SSD).
Sono consapevole che un Raspberry Pi 4 sarebbe molto più performante, ma quanto ci avrei messo ad ammortizzare l’investimento? L’EeePC 701 consuma:
9,5V – 2,5A max → ~24W di picco
frequenza media della CPU su un uptime di 62 giorni: 113 MHz:32.73%, 225 MHz:21.17%, 338 MHz:15.11%, 450 MHz:10.52%, 563 MHz:6.91%, 675 MHz:2.72%, 788 MHz:3.57%, 900 MHz:7.28%
Una stima verosimile si attesta attorno ad una media di 11W
Tradotto in Euro significa:
11 W × 24 h × 365 giorni = 96.360 Wh ≈ 96 kWh / anno
costo medio dell’elettricità in Italia nel 2025 = 0,30 €/kWh 96 kWh × 0,30 € = ~28,80 € / anno
Un Raspberry Pi 4 Model B invece consuma:
4,5 W × 24 × 365 = 39.420 Wh ≈ 39 kWh / anno
39 kWh × 0,30 € = ~11,70 € / anno
Un Raspberry mi farebbe risparmiare circa 17€ l’anno, ma nuovo costa un centinaio di euro e per rientrare dell’investimento mi occorrerebbero circa 6 anni!
Ma veniamo ai problemi pratici: CPU a 32bit e disco da soli 4GB! Forse non ve ne siete accorti, ma la maggior parte delle distribuzioni ha deprecato il supporto all’architettura Intel 32-bit.
Nell’ordine ho quindi scartato:
Debian 12 (supporta i686 ufficialmente “solo” fino a giugno 2028), da amante del retrocomputing non mi ha entusiasmato la scelta di Debian di eliminare il supporto agli Intel a 32bit. L’installazione di base occupa circa 750MB.
Slackware 15/current: stabile, ma è complicato contenere la dimensione del sistema di base. L’installazione della maggior parte dei pacchetti delle serie a, ap, l ed n occupa circa 1200-1300MB, in oltre per il software extra ci si deve affidare a repository non ufficiali o ai maledetti Slackbuild.
Gentoo: RICOMPILARE UNA DISTRO MODERNA SU UN PC A 900MHZ?!!
Slitaz: progetto leggero ed interessante, ma non ha i pacchetti per il software che mi serve.
Tiny Core: stesso discorso di Slitaz.
Free/Net/OpenBSD: girano tutti senza problemi anche su i586, ma l’installazione minima richiede rispettivamente 1.3GB, 900MB e 1.2GB.
Arch Linux 32: uso Arch da 20 anni, c’era ancora installata una vecchia Arch sull’EeePC quando l’ho riesumato, ma mi sono ricordato di questo fork quando ormai era troppo tardi.
Void Linux: ha il miglio rapporto leggerezza-facilità d’installazione. Scartata perché ha un gestore di pacchetti con una sintassi troppo particolare per i miei gusti. L’installazione minima richiede circa 700MB.
Alpine Linux: non è solo sinonimo di container, può essere installata anche su hardware reale. Usa musl al posto di glibc ed è più leggera e performante di tutte le soluzioni precedenti. Purtroppo il suo installer non permette di gestire manualmente le partizioni, ma dato che l’installazione minima richiede meno di 200 MB ho deciso che valesse la pena effettuare l’installazione tramite chroot (stile Arch).
Installazione Alpine Linux tramite chroot
1. Configurazioni base
setup-hostname -n serverino setup-keymap it it setup-timezone -z Europe/Rome setup-interfaces passwd
2. Preparare il disco per btrfs
apk add btrfs-progs cfdisk… [partizioni GPT con sda1 BIOS BOOT e sda2 Linux] mkfs.btrfs /dev/sda2 modprobe btrfs mount /dev/sda2 /mnt cd /mnt btrfs subvolume create rootvol umount /mnt mount /dev/sda2 -o subvol=rootvol,compress=lzo,sdd /mnt mount –bind /dev /mnt/dev mount –bind /proc /mnt/proc mount –bind /sys /mnt/sys mount -t devpts devpts /mnt/dev/pts -o gid=5,mode=620
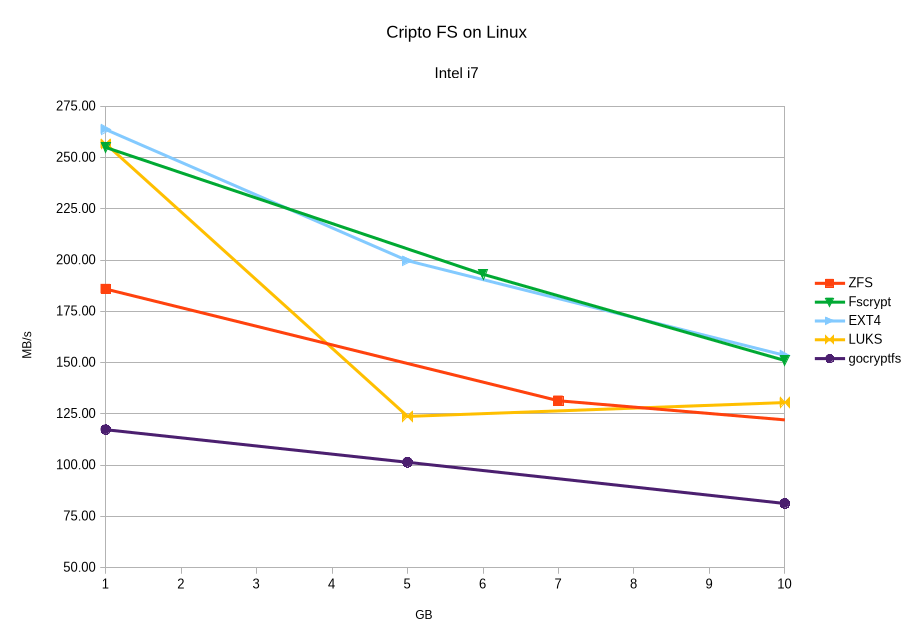
Su un PC con CPU Intel i7-4790K (dotata di accelerazione hardware per l’algoritmo di cifratura aes), 16GB di RAM ed hard disk Seagate Barracuda 7200 da 500GB il supporto per la cifratura integrato nel filesystem ext4 è stato quello che si è comportato meglio in assoluto, con velocità in scrittura praticamente identiche a quelle di ext4 con la cifratura disabilitata. dm-crypt/LUKS è stato più veloce di ZFS con file sotto ai 5 GB. gocryptfs come prevedibile, in quanto strumento user-space, è stato il filesystem più lento tra i 4.
Dettagli del test
Sono state create 3 partizioni sul disco:
una formattata con ext4 (con due cartelle da cifrare rispettivamente con FScrypt e gocryptfs),
un volume dm-crypt/LUKS formattato in ext4 # cryptsetup luksFormat --cipher aes-xts-plain64 --key-size 512 --hash sha512 --iter-time 5000 /dev/sdc2 # cryptsetup open /dev/sdc2 lukspart # mkfs.ext4 /dev/mapper/lukspart
un pool ZFS col dataset cifrato zpool create tank /dev/sdc3 zfs create -o encryption=aes-256-gcm -o keyformat=passphrase -o keylocation=prompt tank/encrypted_data zfs load-key tank/encrypted_data zfs mount tank/encrypted_data
Ho generato con dd 3 file rispettivamente da 1GB, 5GB e 10GB contenenti bit casuali
Con rsync ho misurato la velocità di trasferimento di questi file nelle varie partizioni o directory cifrate e per confronto anche con la semplice copia in una partizione ext4 non cifrata. Dopo ogni copia, per pulire la cache ho lanciato il comando “echo 3 > /proc/sys/vm/drop_caches”
time rsync --progress testfile1G /mnt/“filesystemcifrato“ time rsync --progress testfile5G /mnt/“filesystemcifrato“ time rsync --progress testfile10G /mnt/“filesystemcifrato“
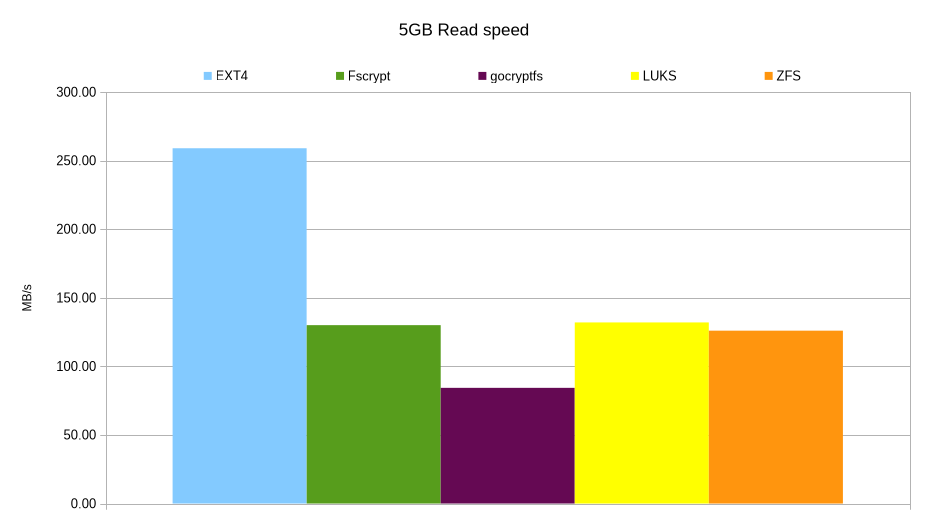
Velocità in lettura
Per completezza ho misurato anche le velocità di lettura col comando:
Stanco delle prestazioni da bradipo dell’emulatore di Android e della (ahimé talvolta necessaria) macchina virtuale con Windows, che grattano di continuo sul disco meccanico della mia home directory, ho deciso che era giunto il momento di intervenire, per evitare di trovarsi catapultati negli anni 90 ogni due minuti.
Per risolvere il problema prestazionale esiste una soluzione molto semplice: comprare un nuovo disco a stato solido, abbastanza capiente. Questa soluzione però non è sicuramente delle più economiche.
La soluzione arzigogolata e nerd invece è: usare un piccolo disco SSD d’avanzo come cache per il disco meccanico.
Configurazione iniziale
Qualche mese fa mi è capitata una rocambolesca avventura per cui ho rischiato di perdere tutti i miei dati per colpa di un programmatore di firmware distratto. Certo, avevo un backup, ma non è la stessa cosa.
Quel giorno comprai dei dischi nuovi e mi feci un bel RAID1, come in figura.
Configurazione attuale, lenta
Questa configurazione avrebbe dovuto aiutarmi a prevenire perdite di dati, e anche a migliorare le performance in lettura dei dischi. Tuttavia, come ben presto si è rivelato, le cose non stavano affatto così, almeno quando i dischi venivano (ab)usati dalle sopraccitate applicazioni, particolarmente avide di random IO.
Il sistema operativo risiede comunque su un disco SSD a parte.
Nuova configurazione
Avendo un disco SSD d’avanzo, che avevo usato per rinsavire il computer portatile che mi ha accompagnato per numerosi viaggi in treno avanti e indietro per l’Università, ho quindi deciso di modificare la mia configurazione nel seguente modo.
Nuova configurazione desiderata
In questo modo, ogni volta che viene effettuato un accesso ad un file sul mio filesystem, LVM si preoccupa di controllare se, per caso, tale accesso può essere fatto anche per mezzo di una copia che si trova sul disco SSD.
Sì, LVM probabilmente potrebbe gestire direttamente anche il RAID, ma per il momento ho preferito riutilizzare le conoscenze già acquisite e continuare a sfruttare il RAID con mdadm.
La torre di Hanoi
Mi sono fatto prestare un disco meccanico di capienza identica ai miei dall’Officina Informatica del GOLEM.
Copiare tutto su quel disco e ricopiare di nuovo sul RAID? No, ho già trovato un disco col firmware buggato, e non desidero trovarne altri. Figuriamoci usare un disco usato di recupero!
Fare una specie di torre di Hanoi e rischiare comunque di perdere i dati per qualche errore umano (da me commesso)? Sì, facciamolo.
Mi sono quindi portato nella seguente situazione, installando il disco meccanico di passaggio, nominato sdd.
Vecchia e nuova configurazione (parziale) a confronto. A sinistra l’array md0, a destra md1.
Poiché è molto facile fare confusione con i nomi, e poiché LVM permette di usare nomi mnemonici, ho assegnato i seguenti nomi autoesplicativi ai vari componenti del mio spazio di archiviazione.
picostorage: il gruppo virtuale;
slowdino: il volume sul vecchio lento dinosauro meccanico (il RAID1);
fastrabbit: il volume sul nuovo veloce disco SSD;
metaguy: il volume per i metadati;
Ho impostato la nuova configurazione, ma con un disco mancante (in rosso in figura).
A questo punto, la cache è attiva. Non rimane che colmare il buco dell’array con uno dei dischi del vecchio array: simulo un guasto a uno dei dischi, lo rimuovo dall’array originale, cancello i metadati, e lo inserisco nel nuovo array.
Mi trovo quindi in questa condizione, e attendo pazientemente che l’array su sdb venga ricostruito, controllandolo con mdstat.
Una volta ricostruito l’array correttamente su sdb e su sdd, ripeto l’operazione, simulando stavolta il fallimento di sdd, e inserendo nell’array sda. Al termine dell’operazione, mi trovo con i miei due dischi sda e sdb nella nuova configurazione, e posso restituire sdd al GOLEM.
In nessun momento di tutta questa procedura i miei dati sono stati su un disco soltanto, perciò si può dire che la procedura sia a prova di guasti hardware.
Non sono però sicuro che sia a prova di guasti umani, perciò non fatelo a casa. 🙂
Benchmark
Per verificare se davvero questa cache serve a qualcosa, faccio un veloce test.
A fronte di circa 400 IOPS ottenute prima di installare la cache, adesso ne vengono fatte oltre 4000! 😮 Un risultato più che soddisfacente.
Anche durante l’uso delle applicazioni più avide, adesso la macchina risulta molto più fluida.
Il monitor di sistema mostra chiaramente i miglioramenti in lettura/scrittura dalla cache (in verde chiaro e fucsia), comparati con la lettura/scrittura dai dischi meccanici (in verde e rosso)
Manutenzione
Ogni tanto è bene controllare lo stato della cache e del RAID, e per questo ci vengono in aiuto i seguenti comandi: