(vedi anche parte prima e seconda)
Un’analisi più approfondita dei log
Le soluzioni viste fin’ora funzionavano un po’ come le pompe sul Titanic: ci facevano guadagnare tempo, ma non potevano salvarci dall’affondare.
Se si guardano i log di accesso al sito, a parte i soliti buontemponi che provano ad accedere come admin:admin su WordPress, e che dovremmo comunque bloccare perché hanno rotto il razzo, è facile capire che il server web viene inondato di molte richieste, molto ravvicinate, ma non è facile distinguere uno schema.
git.golem.linux.it:443 119.13.109.229 - - [16/Feb/2025:00:01:17 +0000] "GET /golem/Math/blame/commit/61abb07b5dfbdef0bcd54f95ac7781d030f7139d/db/math.postgres.sql HTTP/1.1" 200 13858 "https://git.golem.linux.it/golem/Math/blame/commit/61abb07b5dfbdef0bcd54f95ac7781d030f7139d/db/math.postgres.sql" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
git.golem.linux.it:443 124.243.172.72 - - [16/Feb/2025:00:01:26 +0000] "GET /golem/Math/blame/commit/1b50e5eddb9d0ac2fc65a932a982ee7e30713df4/Math.alias.php HTTP/1.1" 200 17154 "https://git.golem.linux.it/golem/Math/blame/commit/1b50e5eddb9d0ac2fc65a932a982ee7e30713df4/Math.alias.php" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
archivio.golem.linux.it:443 103.160.107.178 - - [16/Feb/2025:00:01:28 +0000] "POST /xmlrpc.php HTTP/1.1" 404 4818 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
git.golem.linux.it:443 190.92.206.62 - - [16/Feb/2025:00:02:00 +0000] "GET /golem/Math/blame/commit/80361d29115df757f99321901da31a3fdae9291d/README HTTP/1.1" 200 18184 "https://git.golem.linux.it/golem/Math/blame/commit/80361d29115df757f99321901da31a3fdae9291d/README" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
blog.golem.linux.it:443 85.214.107.118 - - [16/Feb/2025:00:02:01 +0000] "POST /wp-login.php HTTP/1.1" 200 7206 "-" "GRequests/0.10"
Ed è per questo che abbiamo deciso di provare a visualizzare queste informazioni in modo diverso. L’immagine seguente mostra un’ora di log del server web nella notte del 16 febbraio 2025.

Ogni puntino bianco rappresenta una visita. In orizzontale, ogni pixel rappresenta il tempo che scorre, 1 pixel per ogni secondo. In verticale, ogni pixel rappresenta un 256esimo dello spazio di indirizzamento IPv4, cioè 16 milioni di indirizzi per ogni pixel. Sono evidenti due motivi:
- una linea orizzontale, in alto a sinistra: si tratta di un bot “tradizionale”, o comunque di qualcuno che ha a disposizione un po’ di macchine, ma non interi datacenter; che però rimane comunque un maleducato, perché fa almeno una richiesta al secondo.
- nebbia a banchi sulla destra: una significativa percentuale (!) di tutto (!) lo spazio di indirizzamento IPv4 (!) che, in modo coordinato, per decine (!) di minuti accede furiosamente (!) al nostro server web!
Chi è il genio?
NetRange: 47.74.0.0 - 47.87.255.255
CIDR: 47.74.0.0/15, 47.80.0.0/13, 47.76.0.0/14
Organization: Alibaba Cloud LLC (AL-3)
ceff1
A questo punto, ciò che ci serviva era uno strumento che fosse in grado di riconoscere questi pattern di comportamenti irresponsabili, e dare un bel ceffone a chi li metteva in atto. Ed è così, che in finesettimana di follia, è nato ceff1.
ceff1 analizza i log del server web, e correla le visite sia temporalmente sia spazialmente, nello spazio di indirizzamento IP. In altre parole, individua aggregati sospetti di visite, o cluster, che potrebbero essere problematici, e, se lo sono, ne calcola l’entità e banna gli indirizzi IP responsabili.
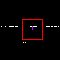
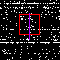
Per esempio, queste immagini rappresentano alcuni cluster identificati dall’algoritmo, basato su K-means.

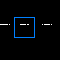
- Il primo cluster è chiaramente un risultato spurio: per la natura intrinseca di K-means, esso categorizza sempre i punti all’interno di un cluster, anche se questi sono sparsi e non rappresentano davvero un problema. Per evitare di considerare malevoli simili cluster, è sufficiente vedere da quanti punti sono composti, e stabilire una soglia minima ragionevole.
- Il secondo cluster è più significativo, ma ancora entro la soglia minima di allarme impostata.
- Il terzo cluster, invece, supera la soglia di riferimento e viene trattato come pericoloso.
- Il quarto cluster raccoglie un numero di visite spropositato da uno spazio di indirizzamento molto vasto, e supera abbondantemente la soglia di riferimento.
Quando un cluster viene identificato come problematico, ne viene calcolato il suo raggio, ossia la sua dimensione in termini di spazio di indirizzamento IP. Detto in altre parole, viene individuato spannometricamente l’intervallo di indirizzi da cui proviene un attacco. Fatto questo, esso viene bannato, a livello di firewall, per un certo tempo. Nelle immagini, questo intervallo è evidenziato da una linea verticale viola (l’algoritmo deve ancora essere raffinato un po’).
Dopo un certo periodo, il ban viene sollevato, e viene eventualmente attivato ancora, se viene nuovamente rilevata attività sospetta dallo stesso intervallo di indirizzi IP.
Questo meccanismo presenta, come tutte le soluzioni, vantaggi e svantaggi:
- capisce dinamicamente l’estensione dell’intervallo di indirizzi da cui proviene l’attacco, così da poterlo bannare in modo più efficace;
- solleva automaticamente il ban dopo un po’, così da tutelare noi da situazioni di attacco temporanee, e tutelare eventuali sfortunati utenti umani da ingiusti ban permanenti;
- può comunque essere accidentalmente impedito l’accesso a degli utenti legittimi che abbiano la sfortuna di utilizzare indirizzi vicini ad altri malevoli, e tutto ciò che questi vedono è che il nostro sito è irraggiungibile.
Di nuovo, il problema è di difficile soluzione, e in più nessuno di noi è uno sviluppatore web professionista, per cui questo programma, al momento, è solo una proof-of-concept.
Anubis
Gli strumenti, imperfetti, descritti fin’ora, sono tutti accomunati da una strategia difensiva, ovvero cercano di evitare i danni dovuti al sovraccarico, semplicemente ignorando le richieste, ma senza fare niente di attivo per prevenirle. È giunta però l’ora di affrontare il problema con una strategia offensiva. Non ne siamo felici, ma non abbiamo altra scelta.
Anubis è uno strumento che pesa la bontà della connessione, esattamente nel modo in cui il dio egizio pesava la bontà delle anime al momento del passaggio nell’aldilà.
Il funzionamento di Anubis consiste nel fornire agli utenti un piccolo problema matematico da affrontare. La soluzione di questo problema, eseguita in modo automatico dal browser, viene ricordata e firmata crittograficamente. Per risolvere il problema, un browser ci mette qualche secondo, mentre il tempo che Anubis impiega per controllare la sua correttezza, in confronto, è del tutto trascurabile. Questa differenza temporale tra quanto ci vuole a risolvere il problema e quanto ci vuole a controllare la correttezza della soluzione, è il punto di forza di Anubis, perché, con poco dispendio di energie, costringe gli utilizzatori del sito a compiere uno sforzo che, in confronto, è enorme.
Un utente legittimo dovrà giusto aspettare qualche secondo, nel mentre che il suo browser risolve la sfida matematica, e solo la prima volta che si collega al sito. Poi la sua soluzione sarà firmata, e dovrà ripetere la prova solo occasionalmente, o solo se inizia a comportarsi in modo anomalo. Un bot invece:
- in genere è meno elaborato di un browser, dunque spesso non sa proprio come risolvere il problema, e semplicemente non riesce a entrare;
- se sa risolvere il problema, può farlo, e impiegherà qualche secondo, cosa che lo rallenta quanto basta affinché non sia un problema per noi; se poi tenta di utilizzare la stessa soluzione troppo frequentemente, gli sarà sottoposto un nuovo problema, così dovrà perdere nuovamente tempo a risolverlo;
- se decide comunque di continuare da un’altro indirizzo IP, sarà comunque identificato come un altro visitatore, e gli verrà sottoposto un nuovo problema da risolvere: a noi non costa niente, a lui costa altri secondi preziosi;
Lato server, non c’è nemmeno bisogno di ricordare niente: tutto lo stato che identifica il bot – o l’utente legittimo – gli viene rispedito indietro firmato digitalmente, così che lui non possa modificarlo. Quando si collega di nuovo, ci basta verificare che la firma sia valida.
Cari bot, eccovi ripagati con la vostra stessa moneta.
Sebbene Anubis sia una possibile risposta a questo problema, si tratta comunque di un software nuovo e ancora immaturo, con molti effetti collaterali, anche se parte di essi sono comuni a software ben più maturi, perché, per mere ragioni tecniche, il problema è di difficile soluzione.
Ad oggi, Anubis può accidentalmente bloccare utenti legittimi, impedire l’accesso a browser vecchi o senza Javascript, e anche a bot buoni. In alcuni casi, di default, l’accesso a bot buoni è impedito per scelta, come specificato nel manuale, ma è un’opzione che può essere modificata nelle impostazioni.
Insomma non sarà perfetto, ma più o meno funziona.
Pentiti, che devi morire!
In natura, esistono delle piante carnivore, che riescono ad intrappolare insetti e piccoli animali nei loro coloratissimi stomaci. Quando una delle loro prede si posa sulla pianta, e si rende conto del suo grave errore, si pente amaramente delle sue azioni, ma ormai è troppo tardi. Questo genere di piante è nominato Nepenthes – “non provar dolore“, non pentirti, non dispiacerti, ormai è tardi. Ispirato a questo genere di trappola, in cui si può entrare ma mai più uscire, è nato il software Nepenthes.
Nepenthes è un generatore automatico di testi che emula i testi umani, in un modo molto più semplice e stupido rispetto ai moderni modelli di intelligenza artificiale generativa. In questo modo, un bot che scandagli il web e capiti su di una pagina generata da tale motore, non sarà in grado di distinguerla da una lunga sequela di supercazzole, e la digerirà come se fosse del normale testo umano da cui apprendere. In questo modo, dunque, Nepenthes avvelena i bot che cadono nella trappola, perché questi essenzialmente impareranno solo supercazzole.
Nepenthes è un software realizzato per creare danno ai modelli generativi in modo deliberato, come sottolineato anche dal suo autore. Ma può essere utilizzato anche per proteggersi dagli attacchi dei bot: se si nasconde abilmente Nepenthes tra le pagine legittime di un sito web, esso sarà trovato solo da bot malevoli, che non rispettano il robots.txt. Utenti umani che dovessero accidentalmente incappare nelle pagine malevole, si allontanerebbero subito, perché nessuno si metterebbe mai a leggere delle pagine piene di supercazzole. Perciò, diventa molto facile distinguere gli indirizzi IP dei bot da quelli degli esseri umani, e bannarli di conseguenza.
Di nuovo, siccome il gioco funziona se generare il testo simil-umano costa meno che rispondere normalmente alle richieste, Nepenthes genera le sue pagine ad una velocità spaventosamente bassa (poche lettere al secondo). In questo modo, oltre all’evidente risparmio in termini di risorse computazionali ed energetiche lato server, si ottengono altri due vantaggi:
- gli utenti umani sono velocemente annoiati dalla lentezza con cui si carica la pagina, perciò la abbandonano
- i bot sprecano tempo prezioso aspettando, lettera per lettera, il testo che giunge loro moolto lentamente
Quando si installa Nepenthes, è necessario prestare particolare attenzione alla configurazione di questo software, perché potrebbe essere possibile far cadere nella trappola anche bot legittimi, come quelli di alcuni motori di ricerca, rischiando così di essere puniti in termini di indicizzazione.
La configurazione di Nepenthes, poi, è un po’ più complessa per scelta:
- è necessario configurare il percorso di una subdirectory, idealmente simile a quelle legittime, in modo da mimetizzarsi meglio sul sito che si vuole proteggere; per esempio, nel caso del GOLEM, il punto di ingresso per la trappola potrebbe essere una pagina apparentemente innocua come https://wiki.golem.linux.it/Lan_Party_2006;
- allo stesso modo, è possibile anche allenare il generatore di testi su dei contenuti a tema, in modo che le supercazzole che genera siano più plausibili, nel contesto di uno specifico sito web; per esempio, nel caso del GOLEM, si potrebbe allenare su alcune delle pagine più corpose del nostro wiki;
- inoltre, il modo in cui bloccare gli attori malevoli, è lasciato totalmente a discrezione dell’utilizzatore; se si pensa che bloccare qualche IP sia cosa da poco, si consideri che il problema è talmente esteso che si tratta di gestire letteralmente milioni di indirizzi, e non è assolutamente facile.
Infine, Nepenthes rimane comunque un software un po’ controverso, perché, oltre a identificare bot malevoli, ha anche il duplice scopo di avvelenare le fonti dalle quali si nutrono, al fine di danneggiare il loro apprendimento. Come dice l’autore, Nepenthes è un software scritto deliberatamente per essere malevolo.
E Cloudflare?
Il problema di bloccare solo i bot malevoli e non gli utenti legittimi, come ha mostrato anche questo articolo, non è di facile soluzione, presenta sfide piuttosto complesse, e qualunque cosa si faccia si rischia comunque di bloccare utenti legittimi, per un motivo o per un altro. Ci sono aziende il cui unico scopo è riuscire a distinguere bot da esseri umani nel modo più accurato possibile, tuttavia, pur disponendo di ingenti risorse, non risolvono il problema. Ad esempio, nemmeno il captcha di Google ci riesce in modo infallibile, e a Cloudflare non sempre interessa collaborare.
Comunque sia, tanto per cominciare, affidarsi a loro sarebbe comunque sbagliato, visto che il loro comportamento non le classifica certo come entità amiche delle piccole realtà. Affidarsi a loro andrebbe solo a rafforzare un oligopolio, costituito dagli unici pochi detentori della conoscenza necessaria a bloccare questi dannati bot. Un oligopolio a cui il web si dovrebbe conformare, come se non lo fosse già abbastanza, e che quindi deprechiamo.
In secondo luogo, il GOLEM ha sempre cercato di essere il più possibile rispettoso della riservatezza dei propri utenti, quindi figuriamoci far passare tutto il traffico dei nostri visitatori da un proxy chissà dove, o condividendo dei cookie traccianti con chissà chi.
Infine, il GOLEM ha sempre cercato di realizzare i suoi obiettivi in autonomia, senza affidarsi a terzi, anche per dimostrare che un’alternativa è sempre possibile, e, quando questo fosse stato impraticabile a causa delle nostre limitate risorse, ha comunque sempre scelto di affidarsi a terzi che condividono i suoi principi, o che almeno sono entità non-nemiche, come OVH per i server, e Mailbox.org per la posta elettronica.
Per cui, cerchiamo di fare del nostro meglio, e vogliate scusarci se ogni tanto questo sito sarà un po’ meno arzillo del solito, o qualche personaggio di un’anime sottoporrà problemi crittografici al vostro browser prima di farvi entrare.
